行业洞察
AI 时代的算力需求与供给之间,存在亟待解决的结构性矛盾
企业算力分散在不同云厂商和数据中心,难以统一管理调度,导致资源利用率低下、重复建设浪费严重。
AI 算力需求复杂,需要专业技术团队搭建维护。中小企业和地方政府难以承担高昂的初始投入和运维成本。
算力采购和运维成本难以精确计量,缺乏统一定价标准,企业无法合理预算和有效控制 AI 应用成本。
不同品牌、架构的 GPU/芯片难以协同工作,国产芯片接入生态不完善,制约了算力的大规模普惠化。
一体化解决方案
四大核心能力,构建完整的算力服务体系
整合分散在各云厂商、数据中心的 AI 算力资源,形成统一的弹性算力网络池。
基于 AI 算法动态分配算力任务,优化资源利用率,确保高效、稳定、低延迟运行。
根据业务需求弹性分配算力,支持训练、推理等不同场景的灵活调度,零起步门槛。
透明计费体系和统一账单,简化成本管理,降低企业 AI 应用的整体支出。
竞争优势
轻资产平台型基础设施服务商,核心差异在于"一体化调度"和"普惠算力"的社会价值。
技术深度
让算力像水电一样随需即取的底层技术支撑
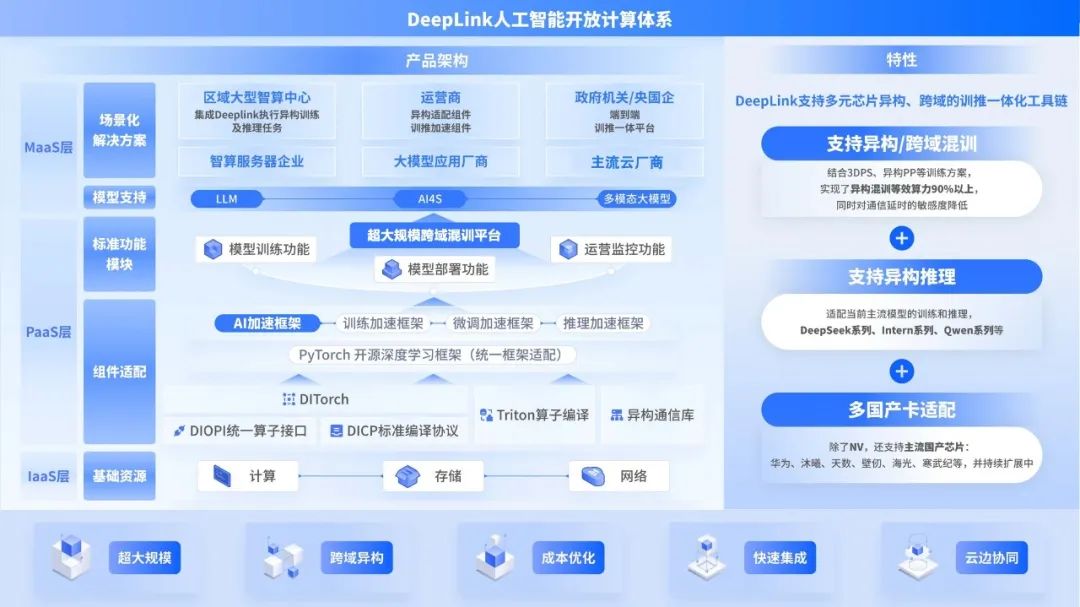
异构混训 · AI加速框架 · 软硬件适配 · 推理加速 · 标准编译协议
将不同算力、品牌的芯片组成更大计算集群进行 AI 训练。异构芯片通信打通 + 并行训练策略双核驱动。
InternEvo 轻量级训练框架,支持千卡集群预训练及单卡微调,在 1024 个 GPU 上实现近 90% 加速效率。
提供设备无关处理单元——Pytorch 扩展包,支持国产芯片高效接入 Pytorch 框架,实现跨硬件无缝迁移。
多层次粒度接口标准,吸收不同架构芯片算子数据排布差异,支持编译模式抓取整图,显著提升推理性能。
通过图获取模块获得深度学习模型计算任务,表达为统一中间表示(计算图),自动生成芯片设备代码,提升研发效率。
支持一键部署与弹性伸缩,提供工具集成能力,让企业无需运维专家即可管理复杂 AI 计算任务。
使命与愿景
让中小企业、地方机构也能低成本使用高性能 AI 算力,打破算力鸿沟。
为地方政府、企业的数字化转型提供可靠的算力底座,推动产业数字化升级。
提供标准化 MaaS API 接口和开放生态,加速 AI 应用落地,繁荣 AI 产业链。
"以算力为基,数据为翼,
驱动智能未来"